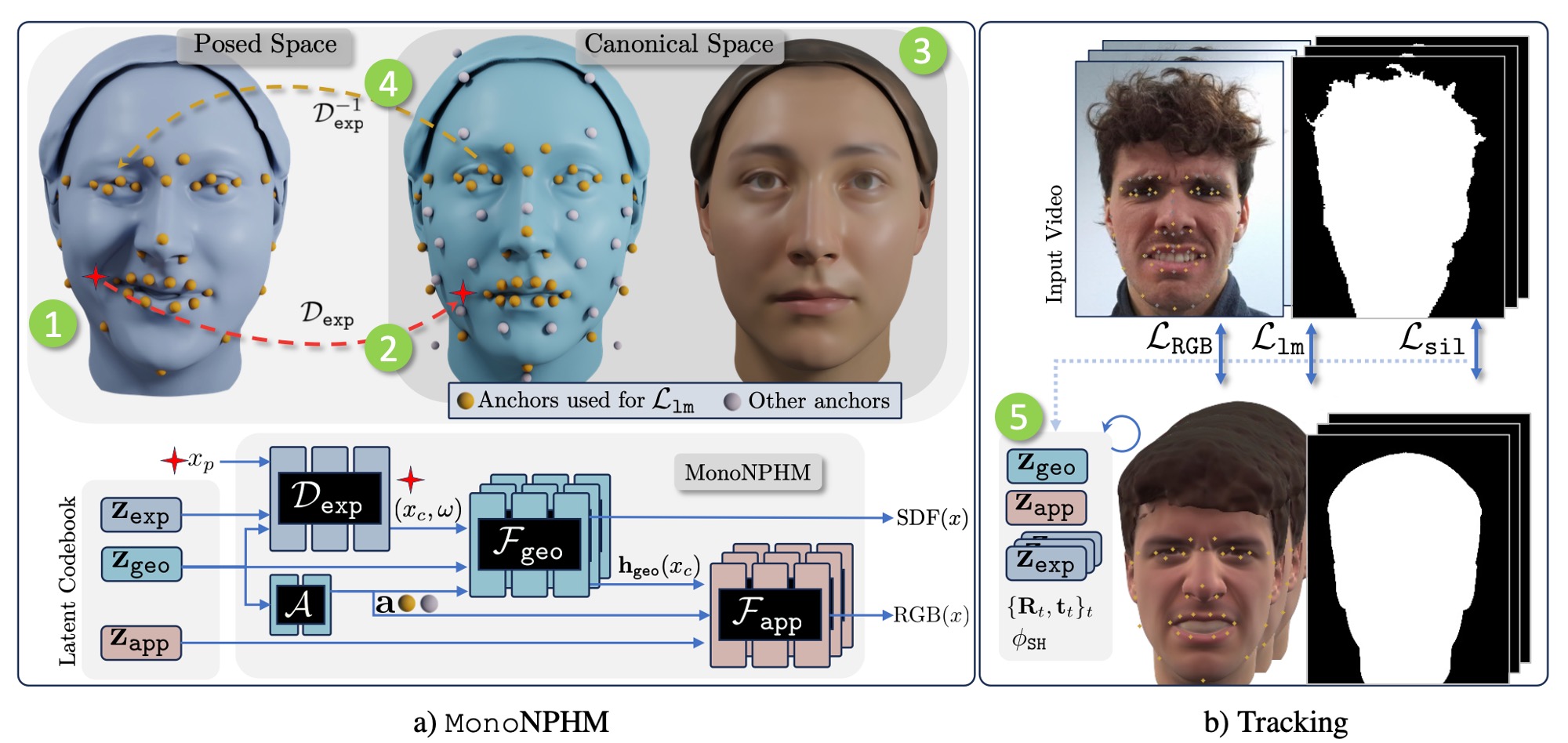
1. Given a point in posed space, we backward-warp it into canonical space.
2. Geometry is represented in canonical space using a neural SDF, which also produces a condition for the appearance.
3. Appearance is modeled using a texture field in canonical space. Conditioning on geometry features ensures more effective gradients from an RGB loss to the geometry code during inverse rendering.
4. Our geometry and appearance networks depend on a set of discrete face anchor points. Using iterative root finding, we can numerically invert the backward deformation field to obtain anchors in posed space.
5. We perform tracking by optimizing for latent geometry, appearance and expression parameters. RGB and silhouette losses are built using deformable volumetric rendering. The landmark loss is computed by projecting posed anchors into image space.