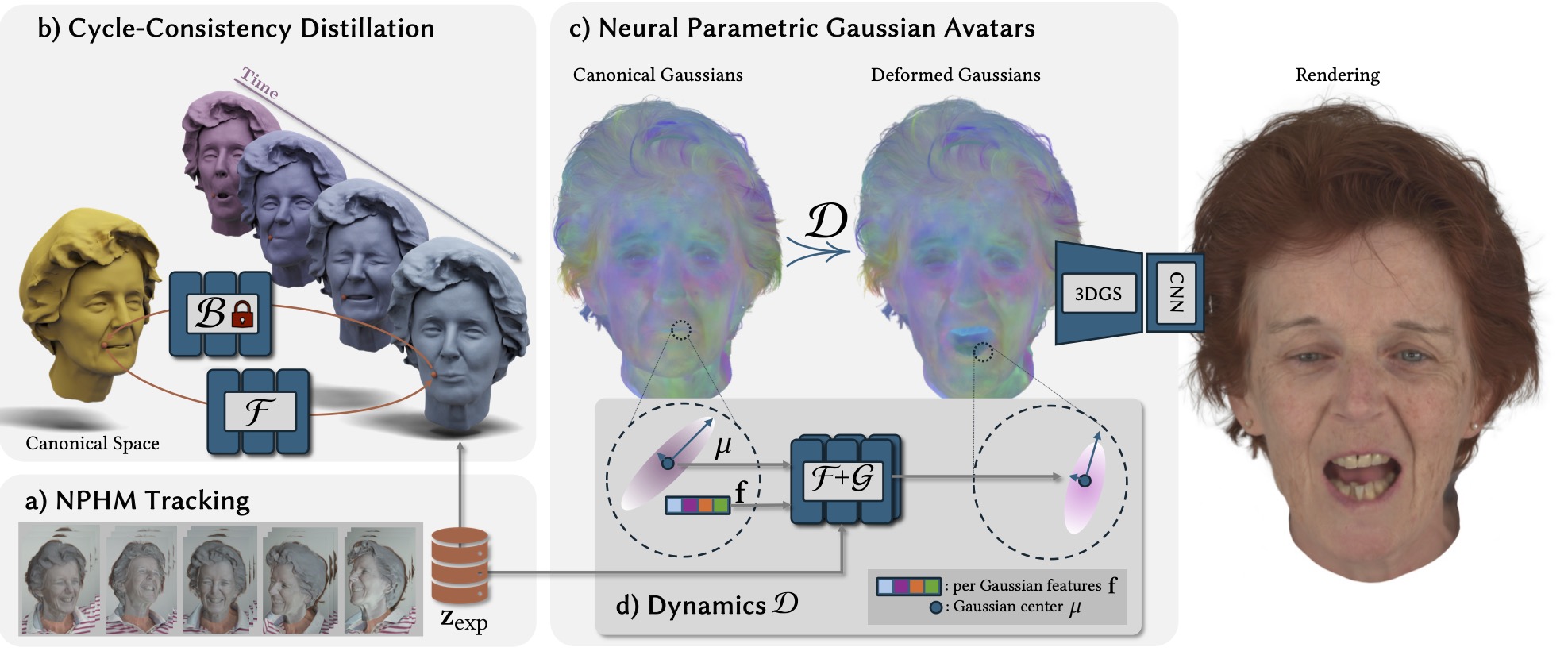
a)
Our method is based on the MonoNPHM model. We track MonoNPHM against COLMAP point clouds computed on the NeRSemble dataset, which results in geometrically accurate model-based trackings.
b)
We propose a cycle-consistency objective to invert MonoNPHM's backward deformation field.
The resulting forward deformation field is directly compatible with rasterization-based rendering.
c)
NPGAs consist of canonical Gaussian point cloud, which is forward warped using the distilled deformation prior F and
second network G, responsible for learning fine-scale dynamic details.
d)
By attaching latent features to each primitive, we lift the input to the deformation fields to a higher dimensional space,
such that each primitive's dyanmic behaviour can be more accurately described.